
Understand RAG AI with this detailed beginner guide explaining Retrieval-Augmented Generation, its benefits, key use cases, and why it’s becoming essential in AI development.
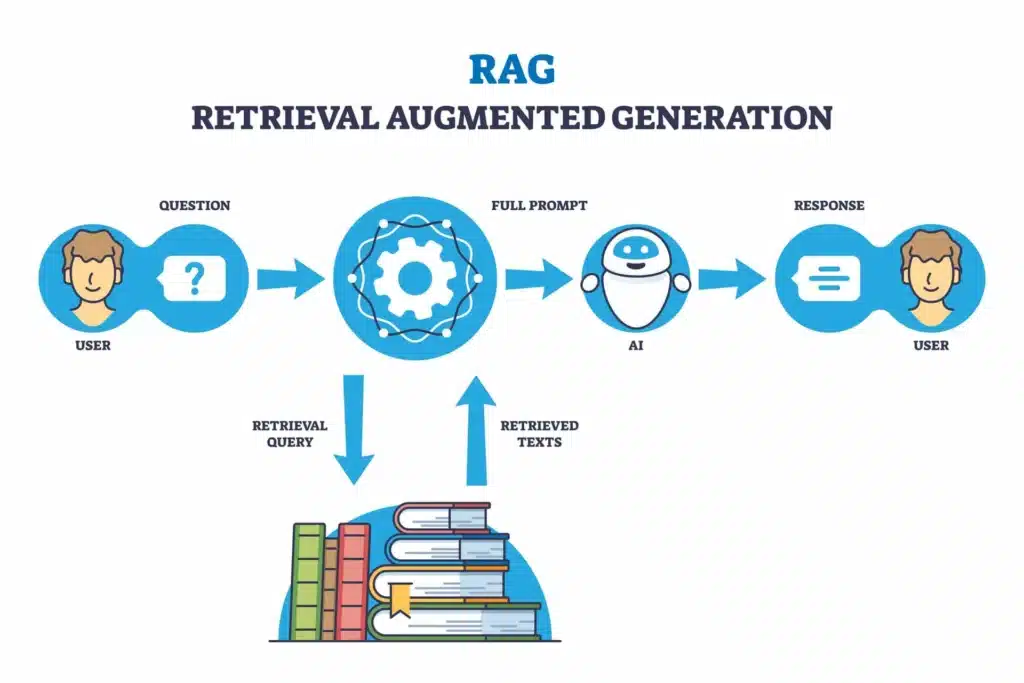
Artificial intelligence continues evolving at a breathtaking pace, introducing technologies that reshape how machines understand and process information. Among these innovations, Retrieval-Augmented Generation (RAG) has emerged as one of the most transformative approaches in 2025, fundamentally changing how AI systems deliver accurate, relevant, and trustworthy responses.
If you have ever wondered how ChatGPT can answer questions about your company’s internal documents or how AI assistants access the latest information beyond their training data, you have encountered RAG in action. This comprehensive guide breaks down everything you need to know about RAG AI in clear, accessible language.
Understanding RAG AI: The Basics
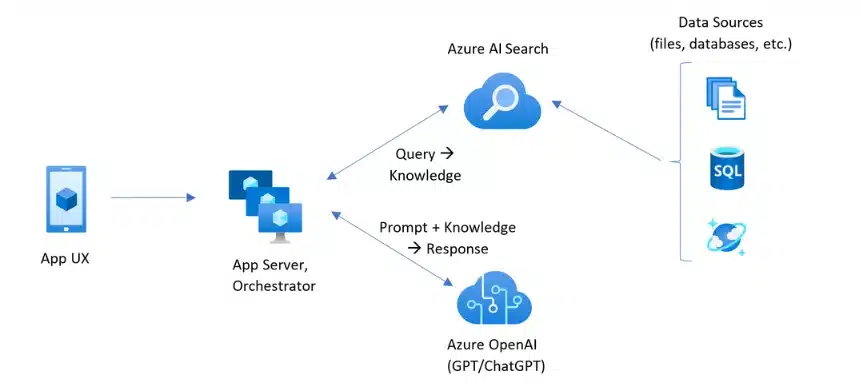
Retrieval-Augmented Generation represents a sophisticated AI framework that enhances large language models (LLMs) by connecting them to external knowledge bases. Instead of relying solely on information learned during training, RAG systems actively retrieve relevant information from authoritative sources before generating responses.
Think of traditional AI models like students taking a closed-book exam. They can only use knowledge memorized during their studies. RAG transforms this into an open-book exam, where AI systems can consult reference materials, ensuring more accurate and current answers.
According to AWS’s comprehensive explanation:
“RAG optimizes large language model output by referencing authoritative knowledge bases outside training data sources before generating responses.”
This approach dramatically improves accuracy, relevance, and usefulness across various contexts. The fundamental innovation behind RAG lies in its two-phase approach:
- Retrieval Phase
- Generation Phase
First, the system searches external databases for relevant information related to your query. Second, it uses that retrieved information to generate informed, contextual responses that go far beyond what the base model could produce alone.
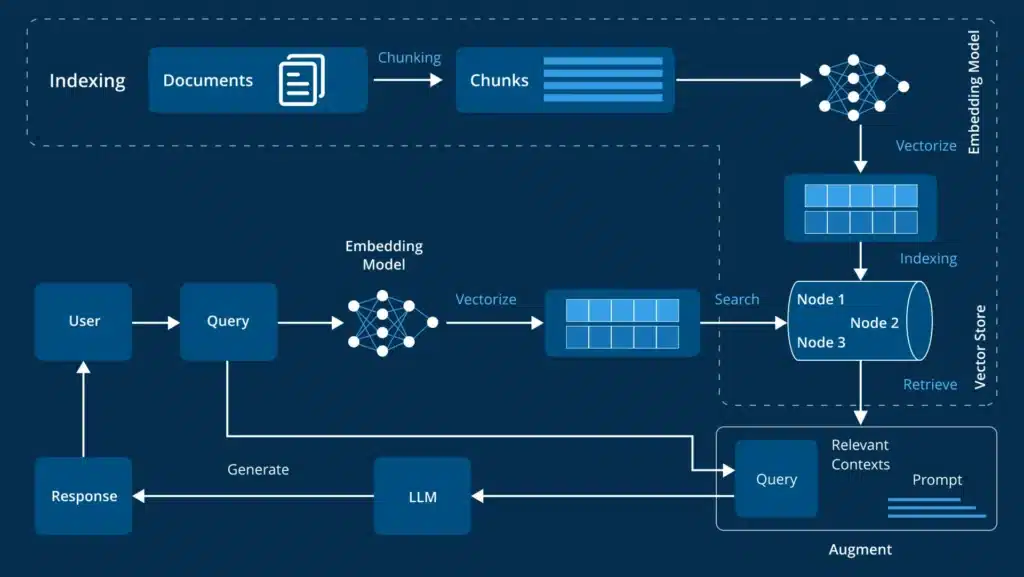
Source: RAG Architecture Diagram
How RAG AI Works: A Step-by-Step Breakdown
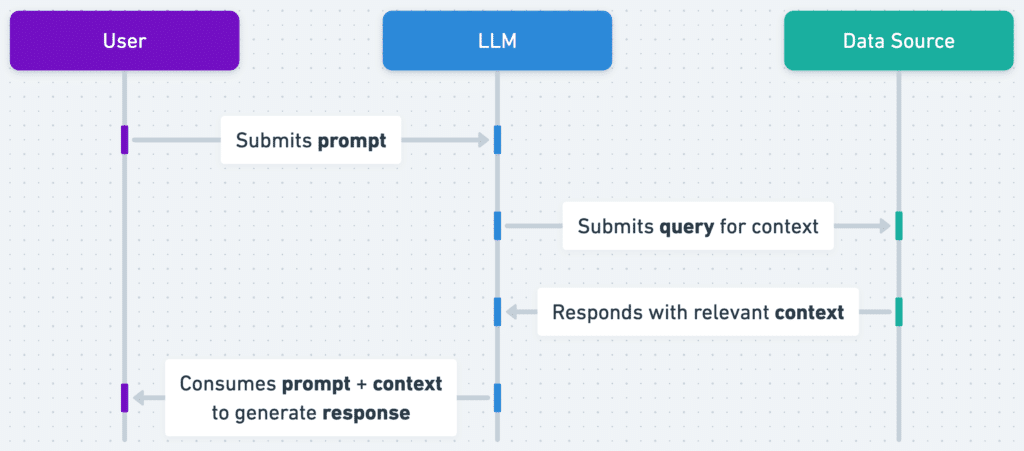
Understanding RAG’s operational mechanics helps demystify this powerful technology. The process follows a structured workflow that ensures accurate, grounded responses.
Step 1: User Query Submission
Everything begins when a user submits a question or prompt. This could be anything from:
“What are the key findings in our Q3 sales report? to Explain the latest research on renewable energy technologies.”
Step 2: Query Embedding and Vectorization
The system immediately converts the user’s natural language query into a mathematical representation called an embedding or vector.
NVIDIA’s detailed blog explains that:
“These numeric vectors allow machines to understand and compare the semantic meaning of text.”
Think of embedding as a coordinate on a massive map where similar concepts cluster together.
“The question What is machine learning? would have coordinates close to artificial intelligence and neural networks but far from cooking recipes.”
Step 3: Information Retrieval from Knowledge Bases
Using the query vector, the retrieval model searches through external knowledge bases to find the most relevant information. These knowledge bases might contain company documents, scientific papers, technical manuals, or real-time data feeds.
The retrieved information could be paragraphs from research papers, sections from product manuals, or entries from databases. The system identifies and extracts the pieces most semantically similar to the user’s query.
According to IBM’s RAG documentation:
“This retrieval component serves as the bridge between static AI models and dynamic, up-to-date information sources.”
Step 4: Prompt Augmentation
The original user query and the retrieved information get combined into an enhanced, augmented prompt. This critical step provides the language model with essential context it would not otherwise have.
The augmented prompt typically follows a structure like:
“Based on the following context: [retrieved information], answer this question: [user query]. Keep your answer grounded in the provided facts.”
Step 5: Response Generation
Finally, the large language model generates a response using both the augmented prompt and its internal knowledge representation. The LLM synthesizes information from the retrieved documents, and it’s trained to create an engaging, accurate answer tailored to the user’s specific question.
Throughout this process, the system can track which sources contributed to the response, enabling proper citation and verification, which builds user trust.
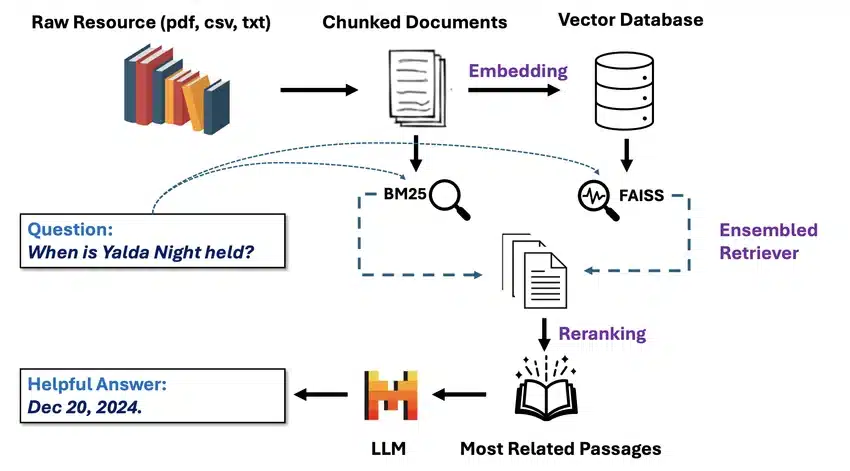
Source: RAG Workflow Visualization
The Critical Components of RAG Systems
Several key components work together to make RAG systems function effectively. Understanding these elements helps appreciate the sophistication behind this technology.
The Knowledge Base
The knowledge base serves as the external information repository that RAG systems query. This could be a company’s internal document library, scientific journal databases, product catalogs, customer service records, or any other structured information source.
Organizations often use vector databases to store this information because they enable fast, efficient similarity searches. Popular vector database solutions include Pinecone, Weaviate, and Chroma.
The Retriever Model
The retriever model handles the critical task of finding relevant information within the knowledge base. It compares the user’s query vector against stored document vectors to identify the most semantically similar content.
Advanced retrievers use sophisticated ranking algorithms to ensure the most relevant information gets prioritized. Some systems employ multiple retrieval strategies simultaneously to maximize coverage and accuracy.
The Integration Layer
The integration layer coordinates all processes within the RAG system. It manages data flow between the retriever and the language model, handles prompt engineering, and orchestrates the overall workflow.
Frameworks like LangChain and LlamaIndex simplify building RAG applications by providing pre-built integration components and standardized interfaces.
The Generator Model
The generator is the large language model that produces the final response. Popular choices include GPT-4, Claude, and other state-of-the-art language models. The generator draws from both the retrieved context and its trained knowledge to create comprehensive, well-articulated answers.
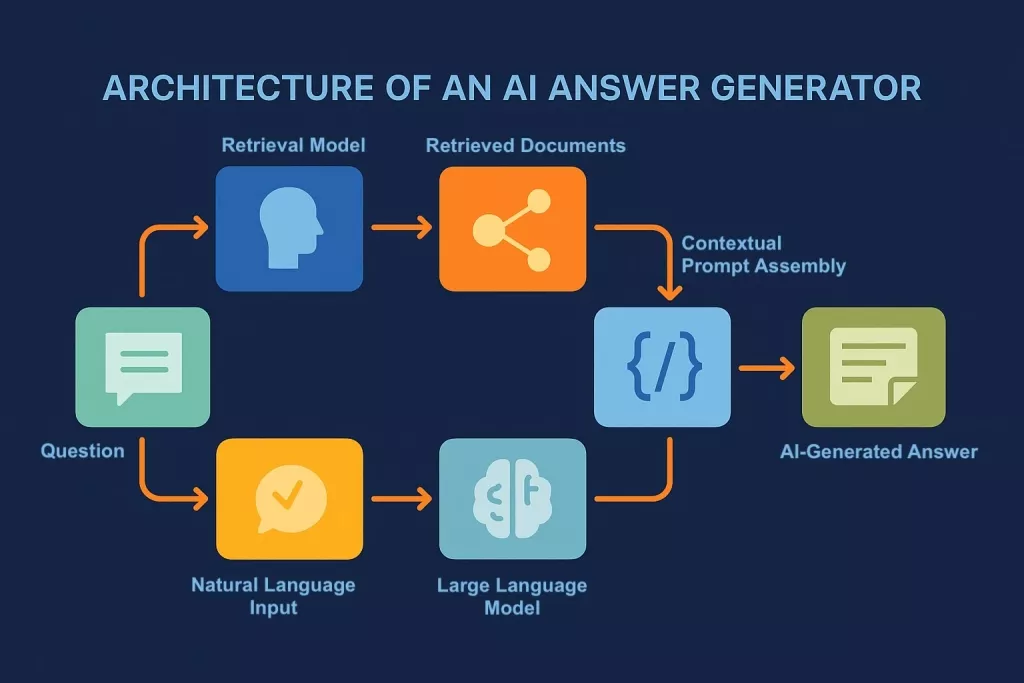
Source: AI Answer Generator
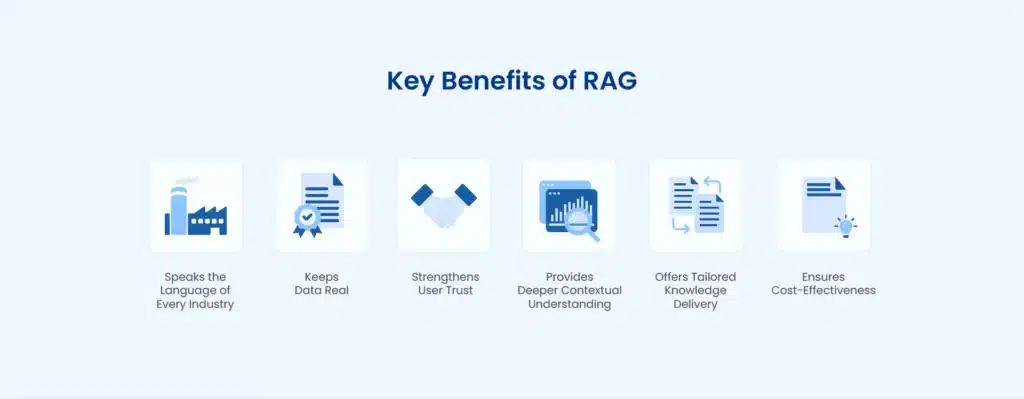
Key Benefits of RAG AI
RAG provides numerous advantages over traditional AI approaches, making it increasingly popular across industries and applications.
Improved Accuracy and Reduced Hallucinations
Large language models sometimes generate plausible-sounding but factually incorrect information, a phenomenon called hallucination.
Wikipedia’s RAG article explains that:
“RAG dramatically reduces these errors by grounding responses in authoritative source material.”
When the AI references specific documents and data, it produces more reliable, verifiable answers. Users can check the cited sources to confirm accuracy and relevance.
Access to Current Information
AI models freeze their knowledge at a specific training cutoff date. A model trained in 2023 cannot accurately discuss events from 2024 or 2025. RAG solves this limitation by connecting models to continuously updated knowledge bases.
Instead of retraining entire models with new data, which is expensive and time-consuming, organizations simply update their knowledge bases. The RAG system immediately begins using the latest information.
Domain-Specific Expertise
RAG enables AI systems to develop deep expertise in specialized fields without requiring massive retraining efforts. A medical RAG system accesses current research papers and clinical guidelines. A legal RAG system references case law and statutes. A customer service RAG system consults product manuals and support tickets.
This specialization happens through knowledge base curation rather than model modification, making it far more practical and cost-effective.
Transparency and Citability
Unlike black-box AI systems, RAG provides clear source attribution. Responses include references to the specific documents or data points used, similar to footnotes in academic papers. This transparency builds trust and allows verification.
According to Pinecone’s RAG guide:
“This citability addresses growing concerns about AI accountability and reliability.”
Cost Effectiveness
Retraining large language models requires enormous computational resources and financial investment. RAG provides a more economical alternative by keeping the base model unchanged while updating only the knowledge base.
Organizations can deploy sophisticated AI applications without the prohibitive costs associated with custom model development and continuous retraining.
Source: RAG Benefits Infographic
Real-World Applications of RAG AI
RAG technology powers diverse applications across numerous industries, solving practical problems and creating tangible value.
Customer Support and Service
Companies use RAG-powered chatbots that access product manuals, troubleshooting guides, and knowledge bases to provide accurate technical support. When customers ask questions, the system retrieves relevant documentation and generates helpful, contextual responses.
This approach ensures customer service AI stays current with product updates and company policies without constant retraining.
Enterprise Knowledge Management
Large organizations struggle with information scattered across countless documents, databases, and systems. RAG enables employees to query this institutional knowledge conversationally, receiving synthesized answers drawn from multiple authoritative sources.
Questions like “What is our vacation policy?” or “Find our Q3 marketing strategy document” get answered by retrieving and summarizing relevant information from HR databases and document repositories.
Medical and Healthcare Applications
Healthcare providers implement RAG systems that access medical journals, clinical guidelines, and patient records to support diagnosis and treatment planning.
IBM Research’s RAG blog highlights:
“How doctors can ask about the latest treatment protocols and receive evidence-based recommendations grounded in current research.”
Legal Research and Analysis
Law firms use RAG systems to search through case law, statutes, and legal precedents. Attorneys can ask complex legal questions and receive answers supported by relevant citations, dramatically reducing research time while improving thoroughness.
Financial Analysis
Investment firms employ RAG to analyze market data, company filings, and economic reports. Analysts can query these systems about specific companies or market trends, receiving responses based on the most current financial information available.
Content Creation and Marketing
Marketing teams use RAG systems connected to brand guidelines, product specifications, and competitor analysis to generate on-brand content. The AI references specific company information while creating blog posts, social media content, and marketing materials.
Source: RAG Use Cases Chart
Implementing RAG: Best Practices
Successfully deploying RAG systems requires careful planning and execution. Several best practices maximize effectiveness.
Curate High-Quality Knowledge Bases
The quality of RAG outputs depends entirely on the quality of the knowledge base. Invest time in collecting, organizing, and maintaining authoritative, accurate information sources. Remove outdated or incorrect information regularly.
Structure documents logically with clear headings, sections, and metadata. This organization helps the retrieval system find relevant information more efficiently.
Optimize Document Chunking
Large documents must be divided into smaller, manageable chunks before vectorization. The chunk size significantly impacts retrieval quality. Too small, and chunks lack context. Too large, and they contain too much irrelevant information.
Experiment with different chunk sizes (typically 200 to 1000 words) and overlap strategies to find the optimal configuration for your specific use case.
Select Appropriate Embedding Models
Different embedding models excel at different tasks. Some specialize in technical content, others in conversational text. Choose embedding models that align with your domain and use case.
Consider using domain-specific embedding models when available, as they often outperform general-purpose models for specialized applications.
Implement Effective Retrieval Strategies
Beyond basic similarity search, implement advanced retrieval techniques like hybrid search (combining keyword and semantic search), re-ranking (ordering results by relevance), and query expansion (generating multiple related queries).
These sophisticated approaches improve the relevance of retrieved information, leading to better generated responses.
Monitor and Evaluate Performance
Continuously monitor RAG system performance using metrics like answer accuracy, response relevance, and user satisfaction. Implement feedback loops that allow users to rate responses and report issues.
Use this feedback to refine knowledge bases, adjust retrieval parameters, and improve overall system quality.
Source: RAG Implementation Guide
RAG Limitations and Challenges
While powerful, RAG systems face several limitations that developers and users should understand.
Latency Concerns
RAG adds processing steps compared to standard language model queries. Retrieving information from large knowledge bases, especially external APIs, can introduce noticeable delays. Organizations must balance comprehensiveness with response speed.
Retrieval Quality Issues
If the retrieval system fails to find relevant information, the generated response will suffer regardless of how sophisticated the language model is. Poor retrieval represents a single point of failure that undermines the entire system.
Context Window Limitations
Language models have maximum context lengths. When retrieved information exceeds this limit, the system must decide what to include or exclude, potentially missing important details.
Evaluation Complexity
Assessing RAG system performance requires evaluating both retrieval accuracy and generation quality. Traditional AI evaluation methods fall short for this hybrid approach. Comprehensive evaluation needs human judgment, relevance scoring, and groundedness checks.
Cost Considerations
While more economical than retraining models, RAG systems still incur costs for vector database storage, embedding model inference, and language model API calls. These expenses scale with usage and knowledge base size.
The Future of RAG AI
RAG technology continues evolving rapidly, with several exciting developments on the horizon.
Agentic RAG
The next generation of RAG systems incorporates AI agents that autonomously decide which retrieval tools to use, when to use them, and how to aggregate results. These agentic systems handle complex, multi-step research tasks with minimal human oversight.
According to Pinecone’s analysis:
“Agentic RAG represents the future of AI applications, moving beyond simple question-answering to sophisticated reasoning and problem-solving.”
Multimodal RAG
Current RAG systems primarily work with text, but future implementations will seamlessly integrate images, videos, audio, and other data types. Users will query across modalities, and systems will retrieve and generate responses using the most appropriate format.
Real-Time RAG
Advances in retrieval technology and model efficiency will enable near-instantaneous RAG responses, eliminating current latency concerns. Real-time RAG will support interactive, conversational applications that feel as responsive as traditional search engines.
Industry-Specific Solutions
Specialized RAG solutions tailored for specific industries (healthcare, legal, finance, manufacturing) will become standard offerings. These vertical-specific systems will incorporate domain expertise, regulatory compliance, and industry best practices.
Conclusion
Retrieval-Augmented Generation represents a fundamental advancement in artificial intelligence, bridging the gap between static language models and dynamic, authoritative knowledge sources. By enabling AI systems to access external information before generating responses, RAG dramatically improves accuracy, relevance, and trustworthiness.
As we move through 2025, RAG has evolved from an experimental technique to an essential architecture for enterprise AI applications. From customer support to medical diagnosis, legal research to financial analysis, RAG powers countless applications that deliver real value to users and organizations.
Understanding RAG is no longer optional for anyone working with AI. Whether you are a business leader evaluating AI solutions, a developer building applications, or simply a curious individual wanting to understand modern AI, grasping RAG concepts provides crucial insights into how the most effective AI systems operate.
The future of RAG looks incredibly promising, with agentic systems, multimodal capabilities, and real-time performance on the horizon. As these technologies mature, we can expect even more sophisticated, reliable, and useful AI applications that truly augment human capabilities.
Frequently Asked Questions
How does RAG differ from fine-tuning a language model?
Fine-tuning involves retraining a language model on specific data to increase its familiarity with a domain, which is expensive and time-consuming. RAG keeps the base model unchanged but connects it to external knowledge bases for retrieval. RAG is more cost-effective, easier to update, and can be combined with fine-tuning for optimal results. Fine-tuning teaches the model domain knowledge, while RAG gives it access to current information.
Can RAG systems work offline without internet access?
Yes, RAG systems can operate entirely offline if the knowledge base is stored locally. Many enterprise implementations run on internal servers with local vector databases, requiring no internet connectivity. This approach provides better security, lower latency, and consistent performance. However, offline RAG systems cannot access real-time web information unless periodically updated.
What types of data can RAG systems access?
RAG systems can access various data types including unstructured text (documents, articles), semi-structured data (tables, spreadsheets), structured data (databases, knowledge graphs), and with multimodal RAG, images, videos, and audio files. The key requirement is that data can be converted into embeddings for vector similarity search.
How much does it cost to implement a RAG system?
Costs vary widely based on scale, complexity, and infrastructure choices. Basic implementations using open-source tools and small knowledge bases can cost just compute resources (potentially a few hundred dollars monthly). Enterprise solutions with large knowledge bases, high query volumes, and premium language models can run thousands to tens of thousands of dollars monthly. Many cloud providers offer RAG-as-a-service options with usage-based pricing.
Does RAG eliminate AI hallucinations completely?
RAG significantly reduces hallucinations by grounding responses in retrieved documents, but it does not eliminate them entirely. Language models can still misinterpret retrieved information or generate text that extends beyond what sources actually say. Proper prompt engineering, source citation requirements, and human oversight remain important for critical applications. RAG makes hallucinations less frequent and easier to detect through source verification.